
인더뉴스 김대웅 기자ㅣ중국 인공지능(AI) 스타트업 딥시크발 충격으로 엔비디아가 하룻새 17% 급락하는 등 미국 증시가 공포에 질렸지만, 이는 오히려 AI 핵심주에 대한 저가 매수의 기회가 될 것이라는 전망이 나온다.
딥시크 모델로 인해 미국 빅테크의 AI 투자가 과도하다는 주장은 무리일 뿐더러, 딥시크가 AI 슈퍼 사이클을 가속화할 것이란 진단에서다. AI 타임라인이 가속화되고 추가 수요를 더 창출할 수 있다는 것이 핵심으로, AI 핵심 인프라 기업에 대한 긍정적 스탠스는 변함없다는 주장이다.
30일 금융투자업계에 따르면 NH투자증권은 딥시크로 인한 최근 글로벌 증시 쇼크에 대해 "시장의 오해로 인해 매수 기회가 발생했다"고 규정했다.
최근 중국 딥시크가 개발한 AI 모델은 전세계 증시에서도 크게 주목받고 있다. 이 모델은 첨단 칩 없이도 세계 상위 10위 안에 드는 성능을 보여줬다. 딥시크의 AI 어시스턴트 앱은 미국 애플 앱 스토어에서 챗GPT를 제치고 무료 앱 1위를 차지하기도 했다.

특히 이 앱은 엔비디아 H800칩을 사용해 비교적 저렴한 비용으로 개발됐고, 이에 미국의 대중국 수출 통제 조치의 효과에 의문이 제기되는 상황이다. 이같은 성과는 AI 분야에서 미국의 주도권과 막대한 투자가 지속될 수 있을지에 대한 의문을 불러일으키기에 이르렀다.
하지만 임지용 NH투자증권 연구원은 "엔비디아와 ASIC 대장인 브로드컴, TSMC 같은 코어 기업들의 업계 내 경쟁력과 해자를 건드리는 이슈가 아니다"고 판단했다. 그는 "마이크로소프트 또는 OpenAI, 구글 등의 Closed End 모델에 대한 위협은 우려 요인"이라면서도 "딥시크 비용 분석에는 검증이 필요한 부분이 많고, 전방위적인 AI 응용처에서의 효용 역시 보장되지 않았다"고 강조했다.
특히 사전 훈련 클러스터에 대한 정보는 전혀 검증되지 않았기 때문에 이를 두고 단순히 비용 효율 측면에서 우위에 있다고 결론 내리기에는 무리가 있다는 설명이다.
임 연구원은 "딥시크에 대한 올바른 해석은 오픈 소스 모델이 독점 모델보다 더 발전 가능성이 높으며 오픈 리서치와 오픈소스 시스템이 채택될 가능성이 더 높다는 의미"라며 "AI 타임라인이 가속화되고 중소 후발주자들도 새로운 가능성을 보여줌으로써 추가 수요를 더 창출할 수 있다는 것이 핵심"이라고 분석했다.
이에 따라 "AI 슈퍼 사이클의 파동은 더욱 진폭을 키우며 전개될 것"이라며 "보다 큰 변동성을 내포한 채로 AI 코어 인프라 기업들의 주가 우상향이 진행될 것"으로 내다봤다. 그는 "컬러(color)는 변할 수 있으나 코어(core)는 변하지 않는다"고 강조했다.
한편, 지난해 중국 항저우에서 설립된 딥시크는 인공지능 일반화(AGI)를 목표로 상업적 응용보다는 기초 기술 개발에 집중하는 AI Lab이다.
시장에서 주목받는 이유는 최근 공개한 오픈소스 딥시크 V3의 높은 GPU 효율성 때문이다. V3 모델은 14조8000억개의 토큰으로 사전 훈련됐고 6710억개의 매개변수로 이뤄졌다. 이는 4050억개의 매개변수를 가진 라마 3.1(메타의 AI 모델)의 약 1.6배에 달하는 크기로 오픈 소스 기준 사상 최대 규모의 LLM(거대언어모델)이다.
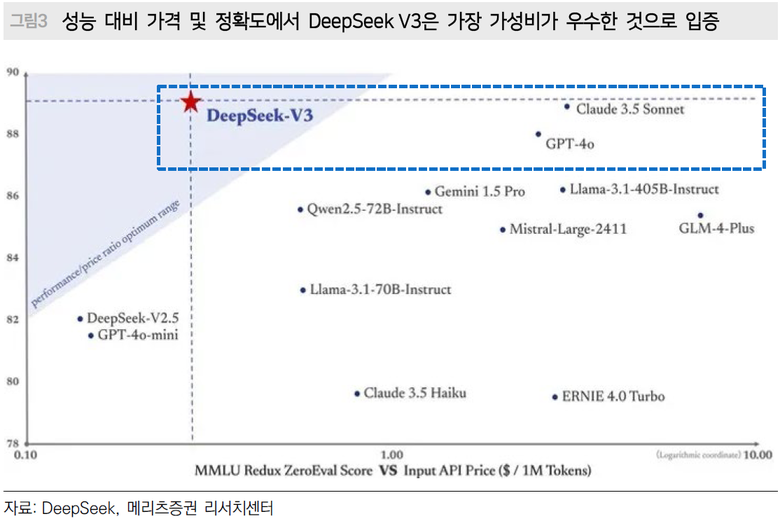
딥시크의 성과는 크게 두 가지 중요한 시사점을 제공한다. 첫째, 미국의 기술 제재에도 불구하고 중국의 AI 기업들은 아키텍처 개선을 통해 하드웨어 한계를 극복하며 미국과의 기술 격차를 줄이고 있다는 점이다. 둘째, 중국 AI 기업들의 치열한 가격 전쟁 및 잇따른 투자 확대로 연결되면서 로컬 AI 반도체 칩 및 인프라 선두기업에 긍정적으로 작용할 것이란 점이다.
최설화 메리츠증권 연구원은 "투자의 관점에서 보면 중국의 AI 기업들이 아직 치열한 출혈 경쟁을 하기 때문에 당장 수익화를 하기 어렵다"면서도 "중국 AI 산업의 개화와 빅테크 중심의 투자 확대는 로컬 반도체 칩 기업과 데이터센터 인프라 선두기업에는 긍정적일 것"이라고 진단했다.
이어 "중국의 AI 모델이 기술혁신을 통해 효율화되면서 저사양의 국산 칩 활용이 더욱 수월해졌다"며 "트럼프 2기 행정부에서도 미국의 대중국 기술 제재가 더욱 강화될 수밖에 없으며 국산 대체에 대한 필요성은 더욱 높아지게 될 것"으로 내다봤다.



![[iNTheScene] 이억원 금융위원장 코스피 4000 돌파 “새로운 도약 출발점”](https://www.inthenews.co.kr/data/cache/public/photos/20251044/art_17615676200702_514d97_120x90.jpg)













